Short foreword:
There will be animated gifs in other posts.
Foreword:
This post is quite tech-heavy and may not be for everyone. If you enjoy such stuff though, there will be more posts of this kind all of which will be tagged “ImplDetails”. There will also be posts with pictures nice to look at or stories nice to read at when production progresses to a point where such things matter more. Don’t forget to subscribe, follow, like or do all of that if you don’t want to miss a thing.
Word:
In my game “Gas Water Dirt BOOM” (name subject to change) currently in development as in many computer programs data has to be serialized in order to be stored. You know, like in take a graph of objects and make a line of bytes out of them which is sufficient to reproduce an equivalent graph of objects out of it. There are common readily available solutions to that problem of which I decided to use none and brew my own instead. Let me point out why and how.
Requirements
There are some requirements I set for my serialization system:
Must produce small output
There are serialization systems which produce nicely structured, readable output. This is cool as long as the product is in-house and you are still debugging the serialization stuff itself. Later on, these are just warming the planet unnecessarily producing data nobody actually needs (exaggeration intended). An XML serializer, for example, will happily encode a 4-byte integer named “Hans-Peter” storing its maximum value as <Hans-Peter>2147483647</Hans-Peter>. That’s 35 characters to store a 4-byte integer let alone most of those also apply some formatting and thus produce even bigger output. What I want my serializer to output is 0x7FFFFFFF. The number, not the string.
Must be able to handle circular dependencies
If there’s an object that is transitively pointing to itself that’s a circular dependency. This means that you can come back to an object just by following references starting at that object. An example in my project is the relation of the classes “Campaign” and “Level”:
|
1 2 3 4 5 6 7 8 9 10 |
public class Campaign{ private List _levels; } public class Level{ private Campaign _campaign; } /* This is boiled down to the minimum required degree of complexity needed to show you a circular dependency. In reality - surprise - there's some actual implementation */ |
See? In a campaign _levels[0].Campaign points to the caller itself.
Now the problem with this is that if you just go ahead and serialize the sh*t out of an object of type Campaign you will need quite some time because there will be a recursion lacking an exit condition:
|
1 2 3 4 5 |
Serialize Campaign Serialize Campaign's First Level Serialize Campaign's First Level's Campaign Serialize Campaign's First Level's Campaign's First Level // You get the point... |
Must be able to perform late binding
To be able to serialize fields of abstract types, interfaces or base types or such, you have to store type information of some sort. This is necessary to know which type to use during deserialization. So, for example, the class Level above actually stores its Campaign in a field of type ICampaignMutable. The serializer can easily use reflection to know which concrete type to use. The deserializer, on the other hand, has to get information about which type to use out of the serialized data. So ideally according to the requirement of small output such dynamic type data would only be written if the type is bound lately. There is no need to tell the deserializer that what to deserialize is an integer when it already knows by itself. An ICampaignMutable, on the other hand, could potentially be a lot of types. Type information also should be small and boy should it be unique. You see where this is going, right?
Must be able to handle changing code
Because I use my serialization system for persistence, the codebase may change between serialization and deserialization. There are two main problems to handle:
- Renaming types
- Adding fields to or removing fields from types
The first one is only a problem if you store type information for late binding using the type’s name (I won’t). For example, when you use dotNet’s built in BinaryFormatter you are basically screwed the moment you tell ReSharper to adjust namespaces (namespaces are part of the fully qualified name of a type). There are solutions to this particular problem but they are not easy to handle.
The second one though means the serialization system has to be able to deserialize data that was stored with an older version of it. Let’s suppose a new field _name was introduced to Campaign. The newer version of the deserializer has to be able to handle the case when this field is not present in the serialized data. Same applies to the removal of fields.
Must Fit nicely into a dependency injection environment
In some types, there are references to services that are injected into them. Those services don’t belong to the serialized data but to the system using that data. The Campaign class, for example, holds a reference to a LevelFactory in order to be able to, well, make levels. It’s an object that’s not serialized and which, during deserialization, is already available in the application deserializing and has to be injected afterwards.
Implementation
Note: I don’t care much about strictly sticking to UML standards. I use MML (My Markup Language, it’s highly volatile). Solid arrows mean “has a”, hollow arrows mean “is a”. That’s about it. I read in a book by Uncle Bob that it’s ok as long as everybody gets the point.
With the requirements laid out, let’s have a look at the actual implementation. At the very basic level, there are three types involved. BinarySerializer, BinaryDeserializer and BinaryTypeSerializer.
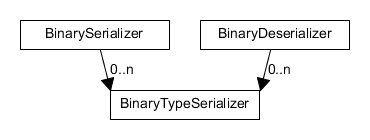
BinarySerializer and BinaryDeserizer offer services to the outer world as well as services to BinaryTypeSerializers.
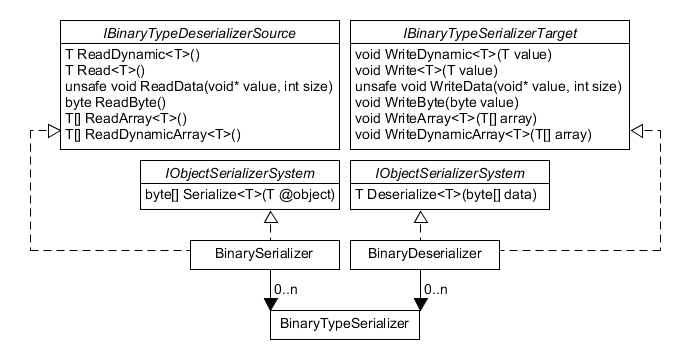
BinaryTypeSerializers offer services to BinarySerializer and BinaryDeserializer and are injected into them.
As you maybe can already tell from the graphs, the serializers themselves can’t do anything themselves but to read and write bytes or successive data. So there’s a nice separation of concerns as serializers manage the way graphs of objects are handled and type serializers know how a specific type has to be formatted.
Implementation of BinarySerializer and BinaryDeserializer
Serializing and Deserializing simple data
Both classes have an internal MemoryStream and offer methods to the type serializers to perform the most basic read / write operations.
|
1 |
private MemoryStream _data; |
|
1 2 3 4 5 6 7 8 9 |
public unsafe void ReadData(void* value, int size) { byte* bValue = (byte*) value; for (int n = 0; n < size; ++n) bValue[n] = (byte) _data.ReadByte(); } public byte ReadByte() { return (byte) _data.ReadByte(); } |
|
1 2 3 4 5 6 7 8 9 |
public unsafe void WriteData(void* value, int size) { byte* bValue = (byte*)value; for (int n = 0; n < size; ++n) _data.WriteByte(bValue[n]); } public void WriteByte(byte value) { _data.WriteByte(value); } |
E.g. in order to write an Int32 to the stream you would do something like the following.
|
1 2 |
int value = 42; target.WriteData(&value, 4); |
Note: Just if you wonder: value doesn’t have to be fixed because being a variable of a value type it’s residing entirely on the stack. Be aware though that in most other cases values have to be fixed.
If you are unable to use unsafe code, you could do the same by utilizing some shifting/masking/looping thingies and calling WriteByte / ReadByte. You’ll figure it out I guess. You shouldn’t be in the first place though. As I found out, even the most picky build targets are cool with it (probably doesn’t apply to unity’s Web Player or WebGL, I haven’t tried).
Serializing and deserializing complex data
Both offer methods to the type serializers to read or write complex types (id est all but bytes and successive data as seen above). In order to handle a type, a typeSerializer for that type has to be registered.
|
1 2 3 4 5 |
private readonly Dictionary<Type, IBinaryTypeSerializer> _typeSerializers; public BinarySerializer(IEnumerable<IBinaryTypeSerializer> typeSerializers) { _typeSerializers = typeSerializers.ToDictionary(each => each.Type); } |
|
1 2 3 4 5 6 7 8 9 10 |
// This is not the actual implementation. public void Write<T>(T value) { Write(typeof(T), value); } private void Write(Type type, object value) { IBinaryTypeSerializer serializer = _typeSerializers[type]; serializer.Write(value, this); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
//Not the actual implementation either public T Read<T>() { return Read<T>(typeof(T)); } private object Read(Type type) { IBinaryTypeSerializer deserializer = _typeSerializers[type]; object result = deserializer.Create(); result = deserializer.Read(result, this); return result; } |
So as you can see, when a complex type is to be (de)serialized, the task is simply delegated to the corresponding typeSerializer.
But wait, there’s more.
Serializing and deserializing null
All fields and variables of reference types in C# can hold the value null. Type serializers shouldn’t have to care much so the (de)serialization of null is handled in the graph serializers (except if the type is serialized by value AND it is a reference type (obviously). I’ll explain later).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
//This is even more useless than the last one. //We're getting there, I promise public const byte ValuePrefix = 34; public const byte ReferencePrefix = 66; private void Write(Type type, object value) { IBinaryTypeSerializer serializer = _typeHandlers[type]; if (value == null) WriteByte(NullPrefix); else{ WriteByte(ValuePrefix); serializer.Write(value, this); } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
//This wouldn't even compile. private dynamic Read(Type type) { byte prefixByte = ReadByte(); if (prefixByte == BinarySerializer.NullPrefix) return null; else if (prefixByte == BinarySerializer.ValuePrefix){ IBinaryTypeSerializer deserializer = _typeDeserializersByType[type]; object result = deserializer.Create(); result = deserializer.Read(result, this); return result; } } |
Every value written with Write(Type) gets prefixed with one byte to distinguish between null and not null.
When the data is deserialized, the deserializer first checks for the null prefix and conditionally returns null.
There will be more prefixes later.
Serializing and Deserializing sets
The (de)serializer offers methods to (de)serialize arrays.
|
1 2 3 4 5 |
public void WriteArray<T>(IReadonlyCollection<T> array) { Write(array.Length); for (int n = 0; n < array.Length; ++n) Write(array[n]); } |
|
1 2 3 4 5 6 7 |
public T[] ReadArray<T>() { int length = Read<int>(); T[] result = new T[length]; for (int n = 0; n < length; ++n) result[n] = Read<T>(); return result; } |
Note: I got used to make paramater types as abstract as possible and return types as specific as possible. Thus I used IReadonlyCollection<T> as the type of the parameter array above.
Pretty straightforward, isn’t it? First, the length of the array is written. The deserializer will need that information at deserialization. After that, all the values are serialized.
Serializing and deserializing (circular) references
Objects which are not serialized “by value” will be serialized only once and after that, a reference to them will be stored. The serializer has a dictionary of all so far serialized objects and their references.
|
1 |
private Dictionary<dynamic, int> _references; |
When an object is serialized, first is checked if it already has a reference and handled accordingly.
If it already has a reference, a reference prefix followed by the reference’s numeric value is written. Otherwise, it’s assigned the next reference value, stored into the reference dictionary and serialized by value with a value prefix.
|
1 2 3 |
public const byte ValuePrefix = 34; // == 0042 public const byte ReferencePrefix = 0x42; public const byte NullPrefix = 42; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// This IS the actual implementation (finally) private void Write(Type type, object value) { IBinaryTypeSerializer serializer = _typeSerializers[type]; if (serializer.ByValue) serializer.Write(value, this); else { if (value == null) WriteByte(NullPrefix); else if (_references.ContainsKey(value)) { WriteByte(ReferencePrefix); Write(_references[value]); } else { _references.Add(value, _referenceCounter); WriteByte(ValuePrefix); serializer.Write(value, this); ++_referenceCounter; } } } |
It is essential that the reference is stored before the object is serialized to avoid a recursive call to serializer.Write(value, this) when there is a circular reference.
The deserializer has a List of all “not by value” objects deserialized so far. Because the deserialization order is strictly the same as the serialization order, a reference’s numeric value equals its index in that list.
|
1 2 |
// Wow... private ArrayList _references; |
When an object that is not “by value” is deserialized, first, the prefix byte is read. The rest of the serialization is handled accordingly.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
// Yep! This is it. Kind of. private dynamic Read(Type type) { IBinaryTypeSerializer deserializer = _typeDeserializersByType[type]; if (deserializer.ByValue) { dynamic result = deserializer.Create(); result = deserializer.Read(result, this); return result; } byte prefixByte = ReadByte(); if (prefixByte == BinarySerializer.NullPrefix) return null; if (prefixByte == BinarySerializer.ReferencePrefix) return _references[Read<int>()]; if (prefixByte == BinarySerializer.ValuePrefix) { dynamic result = deserializer.Create(); _references.Add(result); result = deserializer.Read(result, this); return result; } //If you get here, you are f*cked throw new InvalidOperationException(); } |
Here, instantiation and initialization are two distinct steps. That way, the object itself is already stored in the list of references during its own initialization. So when there is a recursive call to Read(Type) during initialization, the same object will be returned.
Serializing and deserializing dynamically typed data
Any field or variable can store data of its own type or data of all types derived from that type. So in cases where the concrete type of a field is not certain, in addition to the data itself, type information has to be stored.
Every type serializer has a distinct type code, a Guid identifying the type unambiguously.
|
1 2 3 4 5 6 7 8 9 10 |
private readonly Guid _typeCode; public IntSerializer() { _typeCode = Guid.Parse("{90F65427-0349-4029-BF27-C36C8C1359D9}"); } //Parameter will be explained later public Guid GetTypecode(ITypecodeSource typecodeSource) { return _typeCode; } |
The serializer and deserializer offer dynamic variants of Read<T>() and Write<T>(T)
WriteDynamic<T>(T) writes the typecode and then writes the data of the reflected type. If the value is null, it writes Guid.Empty.
|
1 2 3 4 5 6 7 8 9 |
public void WriteDynamic<T>(T value) { if (value == null) Write(Guid.Empty); else { Type dynamicType = value.GetType(); Write(_typeSerializers[dynamicType].GetTypecode(this)); Write(dynamicType, value); } } |
WriteDynamicArray<T>(T[]) writes an array of dynamically typed values.
|
1 2 3 4 5 |
public void WriteDynamicArray<T>(T[] array) { Write(array.Length); for (int n = 0; n < array.Length; ++n) WriteDynamic(array[n]); } |
ReadDynamic<T>() reads the typecode and then uses the corresponding type serializer. If it reads Guid.Empty as the typecode, it returns null.
|
1 2 3 4 5 6 7 |
public T ReadDynamic<T>() { Guid typecode = Read<Guid>(); if (typecode == Guid.Empty) return (T)(object)null; Type type = _typeDeserializersByTypeCode[typecode].Type; return Read(type); } |
ReadDynamicArray<T>() reads an array of dynamically typed values.
|
1 2 3 4 5 6 7 |
public T[] ReadDynamicArray<T>() { int length = Read<int>(); T[] result = new T[length]; for (int n = 0; n < length; ++n) result[n] = ReadDynamic<T>(); return result; } |
Implementation of a typo serializer
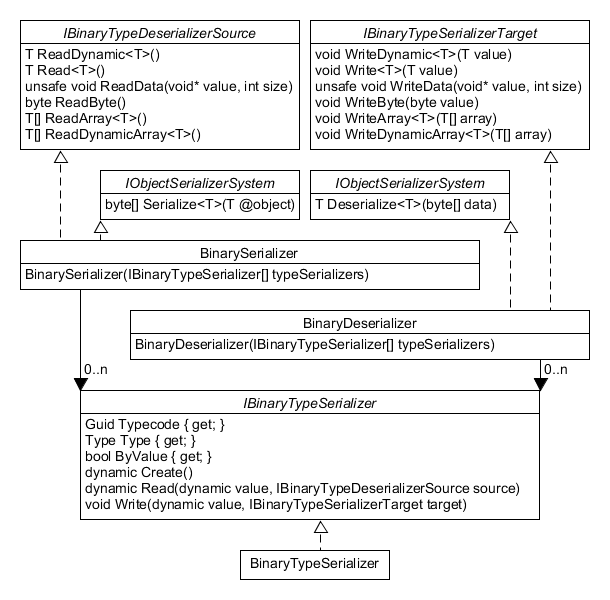
Funny, isn’t it? Anyways. Type serializers are responsible for actually serializing, deserializing and creating complex data.
|
1 2 3 |
object Create(); object Read(dynamic value, IBinaryTypeDeserializerSource source); void Write(dynamic value, IBinaryTypeSerializerTarget target); |
They also hold information needed by the (de)serializer about the type they handle.
|
1 2 3 |
Guid GetTypecode(ITypecodeSource typecodeSource); Type Type { get; } bool ByValue { get; } |
Very, very basic type serializer
Let’s have a look at the IntSerializer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
//BaseTypeSerializer stores the typecode and byValue and provides some typing public class IntSerializer : BaseTypeSerializer<int> { public IntSerializer() : base(true, "{90F65427-0349-4029-BF27-C36C8C1359D9}") { } protected override unsafe void Write(int value, IBinaryTypeSerializerTarget target) { target.WriteData(&value, 4); } protected override int CreateTyped() { return new int(); } protected override unsafe void Read(ref int value, IBinaryTypeDeserializerSource source) { fixed (void* ptr = &value) source.ReadData(ptr, 4); } } |
Note: In a later version of BaseTypeSerializer<T>, T CreateTyped() has been made virtual, throwing a NotImplementedException. That way, a type serializer whiches type is serialized by value doesn’t have to implement a method that’s never called.
As you can see, it’s straightforward. ByValue and the type code are passed to the base type’s constructor. It uses WriteData(void*, int) and ReadData(void*, int) to store and read the 4 bytes integer.
In Read(ref int, IBinaryTypeSerializerSource), the value has to be fixed because being passed by reference, it could be a field of a managed object which is potentionally moved by the garbage collector.
Very basic type serializer
An example of a very basic serializer (which you probably shouldn’t implement this way) is the one below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
public class Campaign { private Guid _id; private string _name; private ObservableList<ILevelMutable> _levels; //[...] public class BinarySerializer : BaseTypeSerializer<Campaign> { public BinarySerializer() : base(false, "{BF30C540-A8D9-495B-AAF5-6CC9DE7A4FB7}") { } protected override void Write(Campaign value, IBinaryTypeSerializerTarget target) { target.Write(value._id); target.Write(value._name); target.WriteDynamicArray(value._levels.ToArray()); } protected override Campaign CreateTyped() { return new Campaign(); } protected override void Read(ref Campaign value, IBinaryTypeDeserializerSource source) { value._id = source.Read<Guid>(); value._name = source.Read<string>(); value._levels = new ObservableList<ILevelMutable>(source.ReadDynamicArray<ILevelMutable>()); } } } |
The type serializer is an inner class of the type serialized, so it can access private fields and methods of it. It doesn’t have to be like this though.
Note how the list _levels is converted to an array when serialized and newly instantiated during deserialization. An alternative approach would be to implement a type serializer for the type ObservableList<T> (don’t google it, I made it). It is generic though and type serializers for generic types are a school of witchcraft of their own. We’ll look at that later.
Versioning in type serializers
Over time, types change. Fields come and go. To be able to read serialized data that has been serialized with an older version of the code, versioning has to be utilized. You should use versioning right from the start if you are not over 9000 % sure that the type serialized is super stable.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
public class BinarySerializer : BaseTypeSerializer<Campaign> { private const int Version = 1; public BinarySerializer() : base(false, "{BF30C540-A8D9-495B-AAF5-6CC9DE7A4FB7}") { } protected override void Write(Campaign value, IBinaryTypeSerializerTarget target) { target.Write(Version); target.Write(value._id); target.Write(value._name); target.WriteDynamicArray(value._levels.ToArray()); } protected override Campaign CreateTyped() { return new Campaign(); } protected override void Read(ref Campaign value, IBinaryTypeDeserializerSource source) { int version = source.Read<int>(); if (version >= 1) { value._id = source.Read<Guid>(); value._name = source.Read<string>(); value._levels = new ObservableList<ILevelMutable>(source.ReadDynamicArray<ILevelMutable>()); } } } |
An integer representing the version of the serialized data is serialized as the first value. It is then read at deserialization and the following code is executed accordingly.
If, for example, a new field string _description would be introduced, the serializer would change to something like this.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
public class BinarySerializer : BaseTypeSerializer<Campaign> { private const int Version = 2; public BinarySerializer() : base(false, "{BF30C540-A8D9-495B-AAF5-6CC9DE7A4FB7}") { } protected override void Write(Campaign value, IBinaryTypeSerializerTarget target) { target.Write(Version); target.Write(value._id); target.Write(value._name); target.WriteDynamicArray(value._levels.ToArray()); target.Write(value._description); } protected override Campaign CreateTyped() { return new Campaign(); } protected override void Read(ref Campaign value, IBinaryTypeDeserializerSource source) { int version = source.Read<int>(); if (version >= 1) { value._id = source.Read<Guid>(); value._name = source.Read<string>(); value._levels = new ObservableList<ILevelMutable>(source.ReadDynamicArray<ILevelMutable>()); } if (version >= 2) value._description = source.Read<string>(); else value._description = "Campaign " + value._name; } } |
The version has been incremented to two. The new field is serialized. It is only deserialized if the version of the serialized data is bigger or equal to two. Otherwise it is initialized with a standard value dervived from _name.
Now let’s suppose the field Guid _id is removed.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
public class BinarySerializer : BaseTypeSerializer<Campaign> { private const int Version = 3; public BinarySerializer() : base(false, "{BF30C540-A8D9-495B-AAF5-6CC9DE7A4FB7}") { } protected override void Write(Campaign value, IBinaryTypeSerializerTarget target) { target.Write(Version); target.Write(value._name); target.WriteDynamicArray(value._levels.ToArray()); target.Write(value._description); } protected override Campaign CreateTyped() { return new Campaign(); } protected override void Read(ref Campaign value, IBinaryTypeDeserializerSource source) { int version = source.Read<int>(); if (version >= 1) { if (version < 3) source.Read<Guid>(); value._name = source.Read<string>(); value._levels = new ObservableList<ILevelMutable>(source.ReadDynamicArray<ILevelMutable>()); } if (version >= 2) value._description = source.Read<string>(); else value._description = "Campaign " + value._name; } } |
Version is incremented to three. _id is no longer serialized. At deserialization though, if version is less than three (id est _id is present in the serialized data), the value no longer needed is read to advance the deserializer by the size of a Guid and get to the position where _name is stored.
Type serializers handling initialization
Some types simply are not ready to go when they are just deserialized. The class Campaign, for example, has an ObservableList<> of levels. After deserialization, it has to register to events of that list in order to, well, actually observe.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
public class Campaign { private Guid _id; private string _name; private ObservableList<ILevelMutable> _levels; //[...] private void RegisterLevels(){ //In reality, this is elsewhere... _levels.Cleared += LevelsOnCleared; _levels.ItemInserted += LevelsOnItemInserted; _levels.ItemRemoved += LevelsOnItemRemoved; _levels.ItemChanged += LevelsOnItemChanged; _levels.ItemMoved += LevelsOnItemMoved; } public class BinarySerializer : BaseTypeSerializer<Campaign> { public BinarySerializer() : base(false, "{BF30C540-A8D9-495B-AAF5-6CC9DE7A4FB7}") { } protected override void Write(Campaign value, IBinaryTypeSerializerTarget target) { target.Write(value._id); target.Write(value._name); target.WriteDynamicArray(value._levels.ToArray()); } protected override Campaign CreateTyped() { return new Campaign(); } protected override void Read(ref Campaign value, IBinaryTypeDeserializerSource source) { value._id = source.Read<Guid>(); value._name = source.Read<string>(); value._levels = new ObservableList<ILevelMutable>(source.ReadDynamicArray<ILevelMutable>()); value.RegisterLevels(); } } } |
Any initialization steps necessary can be done after deserialization. Here, RegisterLevels is called after a Campaign is deserialized.
Type serializers injecting dependencies
As mentioned before, a Campaign holds a LevelFactory which is not serialized but injected during deserialization.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
public class Campaign { private IFactory<ICampaignMutable> _levelFactory //[...] public class BinarySerializer : BaseTypeSerializer<Campaign> { private IFactory<ICampaignMutable> _levelFactory; public BinarySerializer(IFactory<ICampaignMutable, ILevelMutable> levelFactory) : base(false, "{BF30C540-A8D9-495B-AAF5-6CC9DE7A4FB7}") { _levelFactory = levelFactory; } protected override void Write(Campaign value, IBinaryTypeSerializerTarget target) { target.Write(value._id); target.Write(value._name); target.WriteDynamicArray(value._levels.ToArray()); } protected override Campaign CreateTyped() { return new Campaign(); } protected override void Read(ref Campaign value, IBinaryTypeDeserializerSource source) { value._id = source.Read<Guid>(); value._name = source.Read<string>(); value._levels = new ObservableList<ILevelMutable>(source.ReadDynamicArray<ILevelMutable>()); value._levelFactory = _levelFactory; } } } |
After the campaign is deserialized, the level factory is injected. To be able to do so, the serializer itself is dependent on the level factory, which is injected into it.
Generic type serializers
To be able to serialize generic types, one would implement a generic type serializer like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
public class NotSoCleverListSerializer<T> : BaseTypeSerializer<List<T>> { public NotSoCleverListSerializer() : base(false, "{B13A5977-E26F-40EC-8FD3-E9252F7DA277}") { } protected override void Write(List<T> value, IBinaryTypeSerializerTarget target) { target.WriteDynamicArray(value.ToArray()); } protected override List<T> CreateTyped() { return new List<T>(); } protected override void Read(ref List<T> value, IBinaryTypeDeserializerSource source) { value.AddRange(source.ReadDynamicArray<T>()); } } |
The content of the list is serialized as an array. Easy.
There’s just one giant elephant in the room. Every constructed NotSoCleverListSerializer<T> (e.g NotSoCleverListSerializer<int>, NotSoCleverListSerializer<float> etc.) has the same type code. So the deserializer is basically f*cked. It simply won’t be able to determine which type serializer it should use.
To avoid this, the type code of a constructed ListSerializer<T> is computed from its own type code and the type code of T
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
public class ListSerializer<T> : BaseTypeSerializerComputedTypecode<List<T>> { public ListSerializer() : base(false, "{B13A5977-E26F-40EC-8FD3-E9252F7DA277}") { } protected override Guid ComputeTypecode(ITypecodeSource typecodeSource) { return TypeCode.Xor(typecodeSource.GetTypecode<T>()); } protected override void Write(List<T> value, IBinaryTypeSerializerTarget target) { target.Write(value.Capacity); target.WriteDynamicArray(value.ToArray()); } protected override List<T> CreateTyped() { return new List<T>(0); } protected override void Read(ref List<T> value, IBinaryTypeDeserializerSource source) { value.Capacity = source.Read<int>(); value.AddRange(source.ReadDynamicArray<T>()); } } |
The type code is computed by XOr-ing the own type code with the type code of T. The ITypecodeSource needed to do so is the serializer or deserializer, which holds all the type serializers and looks up the type code when needed. BaseTypeSerializerComputedTypecode calls ComputeTypecode only once and stores the result.
Usage
To show how the system is used, I set up some test classes, Foo and Bar (obviously), and implemented type serializers for them. There’s also a class Bar<T> (Ha! Barty!), which is derived from Bar.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
private class Foo { public string StringData; public int IntData; public Bar BarData; public List<Foo> FooDatas; public class Serializer : BaseTypeSerializer<Foo> { private const int Version = 1; public Serializer() : base(false, "{282DB9FC-B0A0-4D59-93D6-5519C5219FAD}") { } protected override void WriteTyped(Foo value, IBinaryTypeSerializerTarget target) { target.Write(Version); target.Write(value.StringData); target.Write(value.IntData); target.WriteDynamic(value.BarData); target.Write(value.FooDatas); } protected override Foo CreateTyped() { return new Foo(); } protected override void ReadTyped(ref Foo value, IBinaryTypeDeserializerSource source) { int version = source.Read<int>(); if (version <= 1) { value.StringData = source.Read<string>(); value.IntData = source.Read<int>(); value.BarData = source.ReadDynamic<Bar>(); value.FooDatas = source.Read<List<Foo>>(); } } } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
private class Bar { public int IntData; public string StringData; public class Serializer : BaseTypeSerializer<Bar> { private const int Version = 1; public Serializer() : base(false, "{21166F59-F6CB-49E7-9967-28D7766B360F}") { } protected override void WriteTyped(Bar value, IBinaryTypeSerializerTarget target) { target.Write(Version); target.Write(value.IntData); target.Write(value.StringData); } protected override Bar CreateTyped() { return new Bar(); } protected override void ReadTyped(ref Bar value, IBinaryTypeDeserializerSource source) { int version = source.Read<int>(); if (version <= 1) { value.IntData = source.Read<int>(); value.StringData = source.Read<string>(); } } } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
private class Bar<T> : Bar { public T TData; public Bar<T> BarData; public new class Serializer : BaseTypeSerializerComputedTypecode<Bar<T>> { private readonly Bar.Serializer _barSerializer; private const int Version = 1; public Serializer(Bar.Serializer barSerializer) : base(false, "{C19729DB-C3EE-46F9-937F-52D80716FCC6}") { _barSerializer = barSerializer; } protected override Guid ComputeTypecode(ITypecodeSource typecodeSource) { return TypeCode.Xor(typecodeSource.GetTypecode<T>()); } protected override void WriteTyped(Bar<T> value, IBinaryTypeSerializerTarget target) { target.Write(Version); target.Write(value.TData); target.Write(value.BarData); _barSerializer.Write(value, target); } protected override Bar<T> CreateTyped() { return new Bar<T>(); } protected override void ReadTyped(ref Bar<T> value, IBinaryTypeDeserializerSource source) { int version = source.Read<int>(); if (version <= 1) { value.TData = source.Read<T>(); value.BarData = source.Read<Bar<T>>(); _barSerializer.Read(value, source); } } } } |
Note: There’s a more elegant way to serialize derived types. Read the quickstart guide for more information.
To actually use the serialization system you first have to do some setup. You can let a Di Container do a lot of the work. Here, I do it manually.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Bar.Serializer barSerializer = new Bar.Serializer(); IBinaryTypeSerializer[] typeSerializers = { new Foo.Serializer(), barSerializer, new Bar<Foo>.Serializer(barSerializer), new Bar<string>.Serializer(barSerializer), new ListSerializer<Foo>(), new ListSerializer<object>() }; typeSerializers = typeSerializers.Concat(BinarySerializationTools.GetAllInternalHandlers()).ToArray(); BinarySerializer serializer = new BinarySerializer(typeSerializers); |
All the type serializers are stuffed into an array and then passed to the serializer. Also, Bar<T>.Serializer is dependent on Bar.Serializer.
To actually have something to serialize, I made an awfully interconnected graph of Foos and Bars.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
Foo foo1 = new Foo(); Foo foo2 = new Foo(); Bar<Foo> bar1 = new Bar<Foo>(); Bar<string> bar2 = new Bar<string>(); foo1.IntData = 12; foo1.StringData = "Foo 1"; foo1.BarData = bar2; foo1.FooDatas = foo2.FooDatas = new List<Foo> { foo1, foo2 }; foo2.IntData = 24; foo2.StringData = "Foo 2"; foo2.BarData = bar1; bar1.BarData = bar1; bar1.TData = foo1; bar1.IntData = 87; bar1.StringData = "Bar 1"; bar2.BarData = bar2; bar2.TData = "Bar 2 typeof(T)"; bar2.IntData = 32; bar2.StringData = "Bar 2"; |
Then I put all of them into a List<object> and serialized it.
|
1 2 3 4 5 6 7 |
List<object> listData = new List<object> { foo1, foo2, bar1, bar2 }; byte[] data = serializer.Serialize(listData); //341 bytes |
Lastly, I deserialized and made sure the resulting graph is equal to the original one.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
List<object> deserialized = deserializer.Deserialize<List<object>>(data); foo1 = (Foo) deserialized[0]; foo2 = (Foo) deserialized[1]; bar1 = (Bar<Foo>) deserialized[2]; bar2 = (Bar<string>) deserialized[3]; Assert.AreSame(foo2.FooDatas, foo1.FooDatas); Assert.AreEqual(12, foo1.IntData); Assert.AreEqual("Foo 1", foo1.StringData); Assert.AreSame(bar2, foo1.BarData); Assert.AreSame(foo1, foo1.FooDatas[0]); Assert.AreSame(foo2, foo1.FooDatas[1]); Assert.AreEqual(24, foo2.IntData); Assert.AreEqual("Foo 2", foo2.StringData); Assert.AreSame(bar1, foo2.BarData); Assert.AreSame(bar1, bar1.BarData); Assert.AreSame(foo1, bar1.TData); Assert.AreEqual(87, bar1.IntData); Assert.AreEqual("Bar 1", bar1.StringData); Assert.AreSame(bar2, bar2.BarData); Assert.AreEqual("Bar 2 typeof(T)", bar2.TData); Assert.AreEqual(32, bar2.IntData); Assert.AreEqual("Bar 2", bar2.StringData); |
Nice.
Making it better (V1.2)
For unknown reasons, I distrust software with a version number of 1.1.
Anyways, now that all the requirements are met, it’s time for new requirements, obviously.
Adhere to the single responsibility principle
Type serializers are passed directly to the serializers which then perform dynamic typing. So the serializers have at least two axes of potential change:
- The way serialization of graphs is handled
- The way dynamic typing is handled
There should be an instance which takes all the type serializers (and other things maybe) and simply resolves a type serializer given either a type or dynamic type data. I defined an interface to a type serializer repository and changed the serializers accordingly.
|
1 2 3 4 5 |
public interface ITypeSerializerRepository { Guid GetTypecode(Type type); IBinaryTypeSerializer GetTypeSerializer(Type type); IBinaryTypeSerializer GetTypeSerializer(Guid typecode); } |
|
1 2 3 4 5 6 7 8 9 |
public void WriteDynamic<T>(T value) { if (value == null) Write(Guid.Empty); else { Type dynamicType = value.GetType(); Write(_typeRepository.GetTypecode(dynamicType)); Write(_typeRepository.GetTypeSerializer(dynamicType), value); } } |
|
1 2 3 4 5 6 |
public T ReadDynamic<T>() { Guid typecode = Read<Guid>(); if (typecode == Guid.Empty) return (T)(object)null; return (T)Read(_typeRepository.GetTypeSerializer(typecode)); } |
Now, this is better. Not good, but it’s ok-ish. The serializers still handle dynamic typing (using typecodes). This should be a concern of the type repository. So I will change the interface to the type serializer repository once more.
Don’t worry, this will lead somewhere soon.
|
1 2 3 4 5 |
public interface ITypeSerializerRepository { IBinaryTypeSerializer GetTypeSerializer(Type type); IBinaryTypeSerializer GetTypeSerializer(IBinaryTypeDeserializerSource deserializer); void WriteTypeInformation(Type type, IBinaryTypeSerializerTarget serializer); } |
|
1 2 3 4 5 6 7 8 9 |
public void WriteDynamic<T>(T value) { if (value == null) Write(Guid.Empty); else { Type dynamicType = value.GetType(); _typeRepository.WriteTypeInformation(dynamicType, this); Write(_typeRepository.GetTypeSerializer(dynamicType), value); } } |
|
1 2 3 4 5 6 |
public T ReadDynamic<T>() { Guid typecode = Read<Guid>(); if (typecode == Guid.Empty) return (T)(object)null; return (T)Read(_typeRepository.GetTypeSerializer(this)); } |
This is nice. The serializers don’t care anymore how type information is stored. BinarySerializer just delegates the task of storing type information to TypeSerializerRepository and BinaryDeserializer gets it’s type serializer passing itself to the type serializer repository which then reads type information and returns it.
There is this principle of “tell, don’t ask“. So here I rather tell the type serializer repository to do its job instead of asking for type codes. Now, type information can be stored in whatever way but just by writing type codes. This is a good thing as soon as resolving dynamic types gets more complicated (which it does).
Implementation of the type serializer repository
This should be easy.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
public class TypeSerializerRepository : ITypeSerializerRepository { private readonly Dictionary<Type, IBinaryTypeSerializer> _typeSerializersByType; private readonly Dictionary<Guid, IBinaryTypeSerializer> _typeSerializersByTypeCode; public TypeSerializerRepository(IEnumerable<IBinaryTypeSerializer> serializers) { //Do not enumerate a possibly computed enumerable twice.. IEnumerable<IBinaryTypeSerializer> serializersArray = serializers as IBinaryTypeSerializer[] ?? serializers.ToArray(); _typeSerializersByType = serializersArray.ToDictionary(each => each.Type); _typeSerializersByTypeCode = serializersArray.ToDictionary(each => each.GetTypecode(this)); } public IBinaryTypeSerializer GetTypeSerializer(Type type) { return _typeSerializersByType[type]; } public IBinaryTypeSerializer GetTypeSerializer(IBinaryTypeDeserializerSource deserializer) { Guid typecode = deserializer.Read<Guid>(); return _typeSerializersByTypeCode[typecode]; } public void WriteTypeInformation(Type type, IBinaryTypeSerializerTarget serializer) { serializer.Write(GetTypeSerializer(type).GetTypecode(this)); } } |
It was. If this would be where it ends, I wouldn’t even bother you with the code. But..
Automatic resolving of generic type serializers
In the use case above, I passed a ListSerializer<object> as well as a ListSerializer<Foo> to the serializers.
There should be a way to simply register ListSerializer<> once and then be ready to go, as long as an IBinaryTypeSerializer<TItem> is registered as well. This is exactly where resolving types from serialized data gets more complex and it is a great thing I already ripped that part off the serializers and put it elsewhere.
So there should be instances which can produce type serializers given a type or some serialized type information.
Interface to a type serializer factory
First of all, a type serializer factory has to be able to determine if it can construct a type serializer for a given type.
|
1 |
bool HasSerializer(Type type); |
Then, obviously, it should give it to the type serializer repository.
|
1 |
IBinaryTypeSerializer GetSerializer(Type type); |
Easy. The tricky part of dynamic typing seems to always lie at the deserialization side. When deserializing, the type serializer repository has to determine which type serializer factory to use out of serialized type information. Good thing we delegated writing and reading type information entirely to it, isn’t it? Identifying what to use with Guids worked well, so let’s do that again. Every type serializer factory is given an id.
|
1 |
Guid Id { get; } |
This is good and well to determine which factory to use but it still doesn’t tell the factory which type serializer to instantiate. So obviously, factories have to store additional type information themselves and be able to read it.
|
1 2 |
void WriteTypeInformation(Type type, IBinaryTypeSerializerTarget target, ITypeSerializerRepository repository); IBinaryTypeSerializer GetSerializer(IBinaryTypeDeserializerSource source, ITypeSerializerRepository repository); |
Usage of type serializer factories
The type serializer repository now gets a set of type serializer factories injected.
|
1 2 3 4 5 6 7 |
public TypeSerializerRepository(IEnumerable<IBinaryTypeSerializer> serializers, IEnumerable<ITypeSerializerFactory> factories) { //Do not enumerate a possibly computed enumerable twice.. IEnumerable<IBinaryTypeSerializer> serializersArray = serializers as IBinaryTypeSerializer[] ?? serializers.ToArray(); _typeSerializersByType = serializersArray.ToDictionary(each => each.Type); _typeSerializersByTypeCode = serializersArray.ToDictionary(each => each.GetTypecode(this)); _typeFactoryByGuid = factories.ToDictionary(each => each.Id); } |
When asked to resolve a type serializer for a given type, the type repository will first check if a type serializer can handle that type and if not, find a type serializer factory which can make one and get the type serializer from there.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
public IBinaryTypeSerializer GetTypeSerializer(Type type) { if (_typeSerializersByType.TryGetValue(type, out IBinaryTypeSerializer serializer)) return serializer; return ResolveFactory(type).GetSerializer(type); } private ITypeSerializerFactory ResolveFactory(Type type) { //Storing factories of already resolved types if (_typeFactoriesByType.TryGetValue(type, out ITypeSerializerFactory factory)) return factory; factory = _typeFactoriesByGuid.Values.First(each => each.HasSerializer(type)); _typeFactoriesByType.Add(type, factory); return factory; } |
To write type information during serialization, the type serializer repository first checks if there is a serializer handling that type and if not, write the corresponding factories id and then let it write its type information.
|
1 2 3 4 5 6 7 |
public void WriteTypeInformation(Type type, IBinaryTypeSerializerTarget serializer) { if (_typeSerializersByType.TryGetValue(type, out IBinaryTypeSerializer result)) serializer.Write(result.GetTypecode(this)); ITypeSerializerFactory typeSerializerFactory = ResolveFactory(type); serializer.Write(typeSerializerFactory.Id); typeSerializerFactory.WriteTypeInformation(type, serializer, this); } |
During deserialization, a guid is read from the serialized data. If there’s a type serializer with that type code, it’s returned. Otherwise, the type serializer factory with that id is picked and used to resolve a type serializer based on the type information in the serialized data.
|
1 2 3 4 5 6 |
public IBinaryTypeSerializer GetTypeSerializer(IBinaryTypeDeserializerSource deserializer) { Guid typecode = deserializer.Read<Guid>(); if (_typeSerializersByTypeCode.TryGetValue(typecode, out IBinaryTypeSerializer typeSerializer)) return typeSerializer; return _typeFactoriesByGuid[typecode].GetSerializer(deserializer); } |
Reduce branching
There is one thing that bugs me about this. In all three cases, first the repository checks for a type serializer and if it doesn’t find one, it checks for a type factory. To avoid this, I made the type serializer repository dependent on factories only. I also made BaseTypeSerializer implement ITypeSerializerFactory, handling just one explicit type.
|
1 2 3 |
public bool HasSerializer(Type type) { return type == typeof(T); } |
|
1 2 3 |
public IBinaryTypeSerializer GetSerializer(Type type) { return this; } |
|
1 2 3 4 5 |
public Guid Id { get { return _typeCode; } } |
|
1 2 3 |
public void WriteTypeInformation(Type type, IBinaryTypeSerializerTarget target, ITypeSerializerRepository repository) { //No additional type information needed. } |
|
1 2 3 |
public IBinaryTypeSerializer GetSerializer(IBinaryTypeDeserializerSource source, ITypeSerializerRepository repository) { return this; } |
e-z. Now the repository has to deal only with factories.
Implementation of an abstract type serializer factory
To make the implementation of type serializer factories easy, I implemented an abstract type to handle the nasty parts like reflection, caching, boilerplate and so on. There are variants for one type parameter (e.g. IBinaryTypeSerializer<List<T>>) and two type parameters (e.g. IBinaryTypeSerializer<Dictionary<TKey, TValue>>).
|
1 2 3 4 5 |
protected BaseTypeSerializerFactoryOneParameter(Type genericTypeDefinition, string idRepresentation) { _serializersByInnerType = new Dictionary<Type, IBinaryTypeSerializer>(); _genericDefinition = genericTypeDefinition; _id = Guid.Parse(idRepresentation); } |
The constructor asks for the generic type definition of the type handled (e.g. List<T>) and an id (Guid) as a string. It instantiates the cache of already resolved types.
|
1 2 3 |
public bool HasSerializer(Type type) { return type.IsGenericType && type.GetGenericTypeDefinition() == _genericDefinition; } |
HasSerializer(Type) checks if the generic type definition of a type is the stored generic type definition (e.g. typeof(List<int>).GetGenericTypeDefinition() == typeof(List<>)).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
public IBinaryTypeSerializer GetSerializer(Type type) { if (!CheckType(type)) throw new InvalidOperationException(); Type genericTypeArgument = type.GenericTypeArguments[0]; if (_serializersByInnerType.TryGetValue(genericTypeArgument, out IBinaryTypeSerializer result)) return result; result = CreateSerializerNonGeneric(genericTypeArgument); _serializersByInnerType.Add(genericTypeArgument, result); return result; } protected abstract IBinaryTypeSerializer CreateSerializer<TInner>(); private bool CheckType(Type type) { return type.IsGenericType && type.GetGenericTypeDefinition() == _genericDefinition; } private IBinaryTypeSerializer CreateSerializerNonGeneric(Type innerType) { return (IBinaryTypeSerializer) typeof(BaseTypeSerializerFactoryOneParameter).GetMethod(nameof(CreateSerializer),BindingFlags.Public|BindingFlags.NonPublic|BindingFlags.Instance).MakeGenericMethod(innerType).Invoke(this, null); } |
Now it is getting interesting. GetSerializer(Type) first checks if there already is a serializer for a given type and if not, it uses some reflection to map the non generic call to CreateSerializer to a call to the generic abstract CreateSerializer<TInner>() which in fact is the only member to be implemented in derived types (except for the constructor).
Implementation of an actual type serializer factory
With this abstract implementation at hand, implementing a factory for a generic type gets next to trivial.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
public ListSerializerFactory() : base(typeof(List<>), "{C073B356-C6FF-4AEF-BC47-F64365DD238A}") { } protected override IBinaryTypeSerializer CreateSerializer<TInner>() { return new Serializer<TInner>(); } private class Serializer<TInner> : BaseTypeSerializerFabricated<List<TInner>> { //byValue = false public Serializer() : base(false) { } protected override List<TInner> CreateTyped() { return new List<TInner>(0); } protected override void WriteTyped(List<TInner> value, IBinaryTypeSerializerTarget target) { target.Write(value.Capacity); target.WriteDynamicArray(value); } protected override void ReadTyped(ref List<TInner> value, IBinaryTypeDeserializerSource source) { value.Capacity = source.Read<int>(); value.AddRange(source.ReadDynamicArray<TInner>()); } } |
BaseTypeSerializerFabricated<T> is a base type of BaseTypeSerializer<T> which doesn’t implement ITypeSerializerFactory<T>.
Reducing dynamic type data (V1.3)
Every time an object is serialized dynamically, type information is stored as a Guid. There is no need to write the same 128 bits of data over and over again though. So, similarly to references, type codes are writen as a reference (a 16 bit unsigned integer) when used repeatedly.
|
1 2 3 4 5 6 7 8 9 |
if (_referencesByFactory.TryGetValue(typeSerializerFactory, out ushort referenceValue)) { serializer.WriteByte(ReferenceByte); serializer.Write(referenceValue); } else { serializer.WriteByte(ValueByte); serializer.Write(typeSerializerFactory.Id); _referencesByFactory.Add(typeSerializerFactory, (ushort) _referencesByFactory.Count); } |
This way, dynamic type data is reduced drastically. The downside is that the serialzation system is now limited to only about 65000 types. I think it will be ok.
Introducing creation data (V1.4)
When I implemented the type serializer for Dictionary<TKey, TValue> I realized that there should be a way to get some data to IBinarySerializer<T>‘s Create() method. Just look at the implementation I came up with without being able to.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
protected override void WriteTyped(Dictionary<TKey, TValue> value, IBinaryTypeSerializerTarget target) { int count = value.Count; target.Write(count); if (value.Comparer == EqualityComparer<TKey>.Default) target.WriteDynamic<IEqualityComparer<TKey>>(null); else target.WriteDynamic(value.Comparer); foreach (KeyValuePair<TKey, TValue> each in value) { target.WriteDynamic(each.Key); target.WriteDynamic(each.Value); } } protected override void ReadTyped(ref Dictionary<TKey, TValue> value, IBinaryTypeDeserializerSource source) { int count = source.Read<int>(); IEqualityComparer<TKey> comparer = source.ReadDynamic<IEqualityComparer<TKey>>(); if (comparer != null) typeof(Dictionary<TKey, TValue>).GetField("comparer", BindingFlags.NonPublic | BindingFlags.Instance).SetValue(value, comparer); for (int n = 0; n < count; ++n) value.Add(source.ReadDynamic<TKey>(), source.ReadDynamic<TValue>()); } |
There are a lot of things I hate in this. Magic strings, unnecessary reflection, ReSharper freaking out, you name it.
Now, the problem is that you cannot implement the type serializer as an inner class of Dictionary<TKey, TValue> so you could set private fields directly. Microsoft carelessly forgot to make all their classes partial.
Joking aside, it’s not really a big deal to implement a solution to that. I just splitted the data written into creation data and initialization data.
|
1 2 3 4 5 6 |
public interface IBinaryTypeSerializer { //[...] void WriteInitializationData(object value, IBinaryTypeSerializerTarget target); void WriteCreationData(object value, IBinaryTypeSerializerTarget target); //[...] } |
Then I pass the deserializer to IBinaryTypeSerializer.Create() et voila, problem solved.
|
1 2 3 4 5 6 |
public interface IBinaryTypeSerializer { //[...] object Create(IBinaryTypeDeserializerSource source); void Initialize(object value, IBinaryTypeDeserializerSource source); //[...] } |
Just have a look at the new implementation of Dictionary<TKey, TValue>‘s type serializer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
protected override Dictionary<TKey, TValue> CreateTyped(IBinaryTypeDeserializerSource source) { int count = source.Read<int>(); IEqualityComparer<TKey> comparer = source.ReadDynamic<IEqualityComparer<TKey>>(); if (comparer != null) return new Dictionary<TKey, TValue>(count, comparer); return new Dictionary<TKey, TValue>(count); } protected override void WriteCreationDataTyped(Dictionary<TKey, TValue> value, IBinaryTypeSerializerTarget target) { target.Write(value.Count); target.WriteDynamic(value.Comparer == EqualityComparer<TKey>.Default ? null : value.Comparer); } protected override void WriteInitializationDataTyped(Dictionary<TKey, TValue> value, IBinaryTypeSerializerTarget target) { target.Write(value.Count); foreach (KeyValuePair<TKey, TValue> each in value) { target.WriteDynamic(each.Key); target.WriteDynamic(each.Value); } } protected override void InitializeTyped(Dictionary<TKey, TValue> value, IBinaryTypeDeserializerSource source) { int count = source.Read<int>(); for (int n = 0; n < count; ++n) value.Add(source.ReadDynamic<TKey>(), source.ReadDynamic<TValue>()); } |
Beautiful. There’s also a nice side effect of this. Type serializers handling basic value types are much cleaner now because they only implement WriteCreationData and Create.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public class DateTimeSerializer : BaseTypeSerializer<DateTime> { public DateTimeSerializer() : base(true, "{60A0E47E-E87B-4736-8338-39543397B2D8}") { } protected override void WriteInitializationDataTyped(DateTime value, IBinaryTypeSerializerTarget target) { target.Write(value.Ticks); target.Write(value.Kind); } protected override DateTime CreateTyped(IBinaryTypeDeserializerSource source) { return new DateTime(source.Read<long>(), source.Read<DateTimeKind>()); } } |
See?
Note: You might ask if one couldn’t simply pass all the data as creation data and conduct the initialization in CreateTyped. There’s still the problem that an object cannot be read by reference as long as it’s being created. So, in order to avoid errors associated with circular references, you always use as few creation data as possible.